思路
爬虫之前要分析下规律,由于**之家的车型不是接口调用的,所以选择用html解析来获取数据,那么车型有4级,我只要把问题化繁为简,就类似获取一个车型下的车系,排量,年款
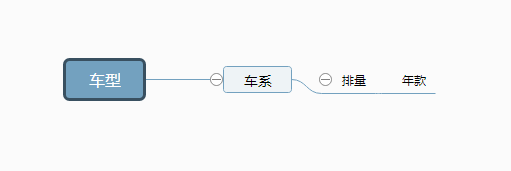
下一级页面跟上一级有关联,所以根据链接进入下级页面,获取数据,这样一直到第四级,这样问题解决了,就在最顶级(车型)一个循环就可以了
库
需要使用到的库有 urllib,xlwt,json,re,beautifulSoup
urllib提供http请求
注:这里遇到一个html乱码问题,只需要设置相应的字符串编码即可
def getHtml(url): page = urllib.urlopen(url) html = page.read() return html.decode('gbk')xlwt写入excel文档
json解析数据
beautifulSoup类jquery一样操作html文档
re正则匹配路由变量
源码下载地址:python爬去车型库