
智能摘要
Jenkins 介绍
Jenkins 是一个功能强大的应用程序,允许持续集成和持续交付项目,无论用的是什么平台。这是一个免费的源代码,可以处理任何类型的构建或持续集成。集成 Jenkins 可以用于一些测试和部署技术。Jenkins 是一种软件允许持续集成。
Jenkins 安装
Jenkis 需要 Java 运行环境,目前最新版需要 Java8,如果已经安装可以忽略
安装 Java 运行环境
列出所有可安装的 rpm 包
yum -y list java*安装 Java8,安装完后使用java -version查看 java 版本
yum -y install java-1.8.0-openjdk*
安装 Jenkin 非常简单,只需要执行下面命令即可
sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat/jenkins.reposudo rpm --import https://pkg.jenkins.io/redhat/jenkins.io.keyyum install jenkinsJenkins 运行
Jenkins 默认端口是 8080,可以通过sudo vi /etc/sysconfig/jenkins修改端口,查找到对应的JENKINS_PORT="9966"修改端口,启动 jenkins
sudo service jenkins startjenkins 就安装完成了,so easy~
在客户端通过浏览器输入http://service-ip:9966远程登录 jenkins 管理系统,出现以下画面,然后按照提示完成系统初始化并下载系统推荐的插件即可

进入系统后,新建一个构建自由风格的任务
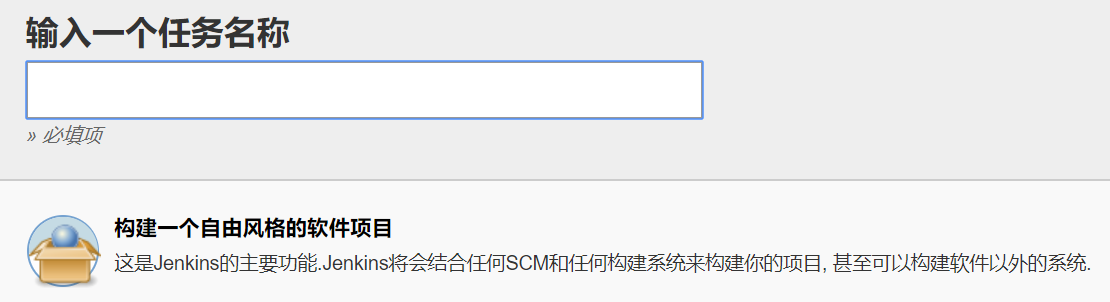
接下来配置的是构建触发器和构建(linux 环境下选择 xshell)两个选项
源码管理配置
git 配置添加凭据,必填的是Username和Private Key
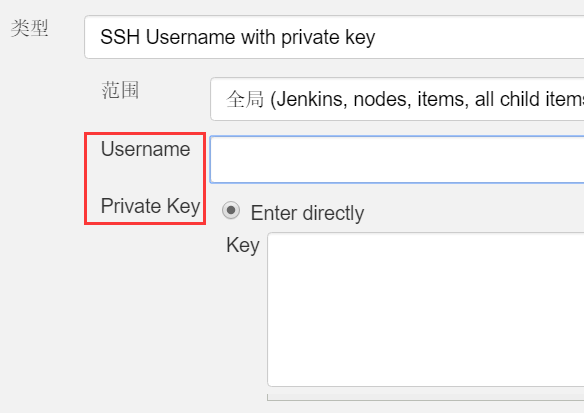
username指的是 jenkins 所属的用户名
private key指的是~/.ssh/id_rsa,如果没有的话,在超级用户下通过命令生成ssh-keygen -t rsa,拷贝里面的/.ssh/id_ras.pub 内容,切换到仓库有权限的的用户下,添加上述拷贝的 id_rsa.pub 内容到当前用户下的`/.ssh/authoried_keys`
构建触发器配置
构建触发器选择远程触发,可以直接通过访问地址来执行构建功能,后面使用 git 钩子来访问这个地址

输入身份验证令牌,随便自己写字符串,比如:sakj123o1jojd5632l,就可以通过下面地址来执行触发构建命令的执行
http://{jenkins-ip}/job/{job-name}/build?token=sakj123o1jojd5632l构建选项输入需要执行的构建命令即可
构建配置
在执行命令的时候有一些坑
1. 执行cd /home/aaa/bb提示无权限
这里需要修改一下 jenkins 的用户是 root 或者其他有权限的用户
vim /etc/sysconfig/jenkins找到$JENKINS_USER="root"修改为有权限的用户名,重启以下 jenkins
service jenkins restart2. 无法执行 npm 命令
由于项目需要执行 npm 来下载依赖包,运行的时候发现npm: command not found,解决方法是在执行 npm 的前面加上以下命令即可
#!/bin/bashexport PATH=/sbin:/usr/sbin:/usr/bin:/usr/local/bin到这里为止就可以通过访问上面的地址http://{jenkins-ip}/job/{job-name}/build?token=sakj123o1jojd5632l顺利执行构建命令
curl 触发构建
在 linux 上可以通过 curl 命令来触发构建,执行下面命令
curl -X POST http://{jenkins-ip}/job/{job-name}/build?token=sakj123o1jojd5632l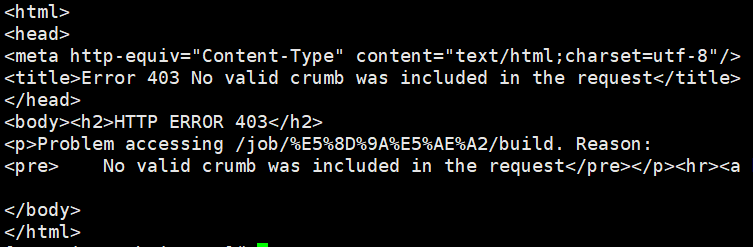
提示 403 错误,No valid crumb was included in the request,网上有一个解决方法是到系统设置->全局安全设置里关闭防止跨域请求伪造这个选项,但是系统有提示有风险,所以还是尽量别使用,于是翻墙找到另外一种解决方法
首先在 linux 上执行下面语句获取 curmb,防止跨站请求伪造需要勾选
curl -u "{username}:{password}" '{jenkinsIp}/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,":",//crumb)'成功了输出如下信息
Jenkins-Crumb:036d4dc7358s8d8d7fcfw1d20dc8fa01接下来在 curl 命令加入请求头里即可
curl -u "{username}:{password}" -H "Jenkins-Crumb:036d4dc7358s8d8d7fcfw1d20dc8fa01" '{jenkinsIp}/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,":",//crumb)'构建失败邮箱提示
进入系统管理->系统设置,配置相关的邮箱 SMTP 配置即可(我这里配置的是 qq),这里需要注意的是
- SMTP 的默认端口是 465 或者 587
- 邮箱的密码不是 QQ 密码,而是 SMTP 的授权码

到此为止,通过 jenkins 就可以实现自动化构建了!



评论